Audio Based Language Identification

Introduction
Language Identification (LI) is an important first step in several speech processing systems and the recommended initial step for Automatic Speech Recognition (ASR). LI is needed for ASR as ASR based systems cannot parse the uttered language in multilingual contexts causing failure in speech recognition. LI allows these systems to automatically recognize the speaker’s language and change its language settings accordingly. We propose an attention based convolutional recurrent neural network (CRNN with Attention) that works on Mel-frequency Cepstral Coefficient (MFCC) features of audio specimens. Additionally, we reproduce some state-of-the-art approaches, namely Convolutional Neural Network (CNN) and Convolutional Recurrent Neural Network (CRNN), and compare them to our proposed method.
Why Deep Learning Approach?
Over the years, studies have utilized many prosodic and acoustic features to construct machine learning models for LI systems. Every language is composed of phonemes, which are distinct unit of sounds in that language, such as ‘b’ of black and ‘g’ of green. Several prosodic and acoustic features are based on phonemes, which become the underlying features on whom the performance of the statistical model depends. If two languages have many overlapping phonemes, then identifying them becomes a challenging task for a classifier. Due to such drawbacks several studies have switched over to using Deep Neural Networks (DNNs) to harness their novel auto-extraction techniques.
Dataset
In the past two decades, development of LID methods has been largely fostered through NIST Language Evaluations (LREs). As a result, the most popular benchmarks for evaluating new LID models and methods are NIST LRE evaluation dataset. The NIST LREs dataset mostly contains narrow-band telephone speech. As the NIST LRE dataset is not freely available and we wanted more modern audio sources, we decided to proceed with IndicTTS dataset, which is open sourced.
IndicTTS is a special corpus of Indian languages covering 13 major languages of India. These include Bengali, Hindi, Marathi, Tamil, Telugu, Assamese, Bodo(India), Gujarati, Kannada, Malayalam, Manipuri, Odia and Rajasthani. It comprises of 10000+ spoken sentences/utterances each of mono and English recorded by both Male and Female native speakers. Speech waveform files are available in .wav format along with the corresponding text.
Preprocessing
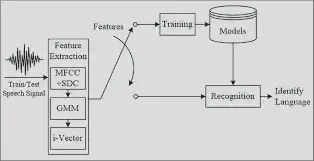
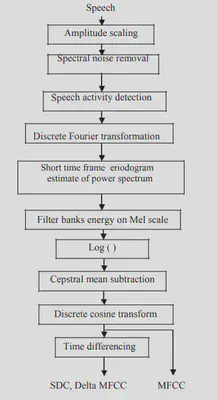
To make our gathered data compatible with our LID system, we need to do some preprocessing. As a first step, we encode all audio files in the uncompressed, lossless WAVE format, as this format allows for future manipulations without any deterioration in signal quality. As phonemes in most of the Indian languages do not exceed 3 kHz in conversational speech, we only include frequencies of up to 5 kHz. We then extracted the features using Mel Frequency Cepstral Coefficients (MFCC).
For more information, check out the code on Github!
V S Abhinav Rahul Gandrakota
Senior Year Undergrad
My research interests include natural language processing, deep learning, artificial intelligence and robotics.